Terraform Outputs: How to with Examples
Terraform outputs expose infrastructure data, enabling cross-module data sharing and integration with external tools for automation and reporting.

Updated: December 8th, 2025
Terraform outputs are a fundamental feature for managing and sharing infrastructure information between Terraform deployments. This guide explains what they are, how they're used, and advanced techniques, including integration with Scalr and Terraform Cloud.
What Are Terraform Outputs?
Terraform outputs are named values that are defined by a Terraform configuration. They are similar to return values in programming languages. You define them within your .tf files to make specific pieces of information about your infrastructure easily accessible after terraform apply.
terraform apply
Initializing plugins and modules...
.....
....
...
..
.
module.scalr_dynamic_vpc_dns.aws_subnet.scalr_subnet[3]: Creation complete after 13s [id=subnet-0ec8755c
12736013f]
Apply complete! Resources: 7 added, 0 changed, 7 destroyed.
Outputs:
subnet_cidrs = [
"10.44.0.0/28",
"10.44.0.16/28",
"10.44.0.32/28",
"10.44.0.48/28",
"10.44.0.64/28",
"10.44.0.80/28",
]
subnet_ids = [
"subnet-0f531658a20a93123",
"subnet-07375ed5d103c2445",
"subnet-0f0cd72e3903c0467",
"subnet-0ec8755c127360668",
"subnet-0d3435b7be22b5890",
"subnet-0c8a43bea6a249567",
]
vpc_id = "vpc-057507a43ddb12345"How Are Outputs Used?
Outputs serve several purposes:
- Displaying Information: Show important resource attributes (e.g., IP addresses, DNS names, ARNs) on the command line after an apply.
- Cross-Configuration References: Pass data from one Terraform configuration (and its state file) to another.
- Integration with Other Tools: Provide data to scripts, CI/CD pipelines, or other automation tools.
Examples of Using Terraform Outputs
VPC ID and Subnet IDs:
resource "aws_vpc" "main" {
cidr_block = "10.0.0.0/16"
}
resource "aws_subnet" "public" {
vpc_id = aws_vpc.main.id
cidr_block = "10.0.1.0/24"
}
output "main_vpc_id" {
value = aws_vpc.main.id
}
output "public_subnet_id" {
value = aws_subnet.public.id
}
S3 Bucket Name:
resource "aws_s3_bucket" "my_bucket" {
bucket = "my-unique-application-bucket-123"
}
output "s3_bucket_name" {
value = aws_s3_bucket.my_bucket.id
description = "The name of the S3 bucket."
}
EC2 Instance Public IP:
resource "aws_instance" "web" {
ami = "ami-0abcdef1234567890" # Example AMI
instance_type = "t2.micro"
tags = {
Name = "WebServer"
}
}
output "web_server_public_ip" {
value = aws_instance.web.public_ip
description = "The public IP address of the web server."
}
After terraform apply, you'll see web_server_public_ip = "X.X.X.X".
Advanced Usage
Maps and Lists: Outputs can return complex data structures.
output "instance_details" {
value = {
id = aws_instance.web.id
public_ip = aws_instance.web.public_ip
}
}
output "subnet_ids" {
value = [aws_subnet.public.id, aws_subnet.private.id]
}
Sensitive Outputs: Mark outputs as sensitive = true to prevent their values from being displayed in plain text in the Terraform CLI or logs. Terraform will still store them in the state file.
output "db_password" {
value = aws_db_instance.main.password
sensitive = true
}
Terraform Output Arguments
The following arguments can be used with outputs:
description (string)
Provides a human-readable explanation of what the output represents. This is highly recommended for documentation and clarity, especially when collaborating on projects.
output "web_server_public_ip" {
value = aws_instance.web_server.public_ip
description = "The public IP address assigned to the main web server instance."
}sensitive (bool)
When set to true, Terraform will redact the output's value in the CLI output (plan, apply, destroy, terraform output). The value is still stored in the state file, but it won't be printed to the console, making it suitable for passwords, API keys, or other confidential information.
output "database_password" {
value = aws_db_instance.main.password
sensitive = true
description = "The root password for the main database. This value is sensitive and redacted from logs."
}depends_on (list of references)
Establishes explicit dependencies between the output and other resources or modules. While Terraform usually infers dependencies automatically based on resource references in the value argument, depends_on can be used in rare cases where an implicit dependency is not sufficient (e.g., if you need to ensure a network rule is applied before trying to connect to an IP exposed by an output, even if the output value itself doesn't directly reference the rule).
resource "aws_instance" "app_server" {
# ...
}
resource "aws_security_group_rule" "allow_ssh" {
type = "ingress"
from_port = 22
to_port = 22
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
security_group_id = aws_instance.app_server.vpc_security_group_ids[0]
}
output "app_server_ip" {
value = aws_instance.app_server.public_ip
description = "The public IP of the application server."
depends_on = [aws_security_group_rule.allow_ssh] # Ensure SSH rule is active before using IP
}ephemeral (bool) - Terraform v1.10+ only
Purpose: When true, this argument prevents the output's value from being persisted in the Terraform state file. This is useful for temporary values that are only needed during a specific Terraform run (e.g., for bootstrapping) and should not be permanently recorded in the state.
This argument is primarily intended for child modules. If you set ephemeral = true on a root module output, terraform output might not work as expected because the value isn't stored. Ephemeral outputs can only be referenced in write-only arguments, other child module ephemeral outputs, ephemeral variables, or ephemeral resources.
resource "random_password" "temp_creds" {
length = 16
}
output "temporary_bootstrap_password" {
value = random_password.temp_creds.result
sensitive = true
ephemeral = true
description = "A temporary password generated for bootstrapping. Not stored in state."
}By understanding and utilizing these arguments, you can make your Terraform outputs more expressive, secure, and tailored to your specific automation and information sharing needs.
Using For Expressions for Complex Outputs
The for expression is a powerful feature in Terraform (and OpenTofu) that allows you to transform, filter, and restructure data directly within an output block before it's exposed to consuming modules or external tools. Instead of simply exporting a raw list or map from a resource, you can use a for expression to iterate over a collection, extract only specific attributes (such as the public IP and DNS name), and then restructure the data into a new, cleaner map or list of objects. This is essential for abstracting complex data: it allows the module developer to select exactly which resource attributes are relevant and present them to the consumer in a predictable, easy-to-use format, ensuring the module's output contract remains stable even if internal resource logic changes.
Imagine your configuration uses count to provision multiple EC2 instances, which results in aws_instance.web being a list of objects.
In your main.tf, you have a list of instances defined:
resource "aws_instance" "web" {
count = 2
ami = "ami-0abcdef1234567890" # Example AMI
instance_type = "t2.micro"
tags = {
Name = "web-server-${count.index + 1}"
}
}In your outputs.tf, you use a for expression to iterate over the list of instances and create a new map:
output "web_server_public_ips" {
description = "A map of Web Server names to their public IP addresses."
value = {
for instance in aws_instance.web :
instance.tags.Name => instance.public_ip
}
}The resulting output is a clean map that is easy for other modules or scripts to consume:
web_server_public_ips = {
"web-server-1" = "192.0.2.101"
"web-server-2" = "192.0.2.102"
}Dynamic Output Indexes
Handling dynamic output indexes is important when dealing with resources or modules created using count or for_each, as these result in a list or map of objects instead of a single object. Since the exact index or key of a specific resource within that collection can be dynamic (or the structure might be confusing), you often need a precise way to extract a single piece of data. For example, if you use count to create a list of instances, you must explicitly specify which element's attribute you want to output: value = aws_instance.web[0].public_ip would reliably retrieve the public IP address of the first instance in the list. This direct indexing is necessary because Terraform cannot automatically infer which specific resource's attribute you intend to expose when multiple resources share the same name prefix.
resource "aws_instance" "web" {
count = 3
# ... other configuration
}
output "first_web_server_ip" {
description = "The public IP address of the first instance created."
# Explicitly reference the element at index [0]
value = aws_instance.web[0].public_ip
}Terraform Outputs Command
The terraform output command can be used to extract and expose information about your deployed infrastructure in a structured and programmatic way. After Terraform successfully applies a configuration, you often need to retrieve specific attributes of the created resources—such as an EC2 instance's public IP address, a load balancer's DNS name, a database connection string, or a storage bucket URL. Outputs make this data readily accessible for various purposes:
- Inter-module Communication: Outputs are essential for passing data between different Terraform modules, allowing you to compose complex infrastructure from smaller, reusable components. For instance, a
networkmodule might output thevpc_idandsubnet_ids, which anapplicationmodule then consumes as inputs to deploy instances into the correct network segments. - CI/CD Pipeline Integration: They serve as a bridge to automation scripts and CI/CD pipelines. An automated pipeline might deploy an application, then use
terraform output app_urlto retrieve the deployed application's URL, passing it to a subsequent testing stage to run end-to-end tests.
Child Module Outputs
You access child module outputs by referencing the module block itself, followed by .outputs and then the name of the output. This allows the parent module to consume values exposed by its nested configurations.
For example, if you have a module named network with an output vpc_id, you would access it in your root module like this:
module "network" {
source = "./modules/network" # Path to your network module
}
output "main_vpc_id_from_module" {
value = module.network.outputs.vpc_id
}Using Outputs from One State File in Another
This is critical for managing complex infrastructure across multiple configurations. The terraform_remote_state data source is your tool for this.
In this scenario, let's imagine you have a network Terraform configuration that creates a VPC and subnets, and an application Terraform configuration that deploys EC2 instances into those subnets.
1. Network Configuration (network/main.tf):
resource "aws_vpc" "main" {
cidr_block = "10.0.0.0/16"
}
resource "aws_subnet" "public" {
vpc_id = aws_vpc.main.id
cidr_block = "10.0.1.0/24"
}
output "vpc_id" {
value = aws_vpc.main.id
}
output "public_subnet_id" {
value = aws_subnet.public.id
}
main.tf
Run terraform apply in the network directory to create the Terraform state file.
2. Application Configuration (application/main.tf):
Now, you want to define the remote state in the application Terraform configuration file. Once defined, you can use the data.terraform_remote_state.network.outputs.public_subnet_id data source to pull the output from the network state file:
data "terraform_remote_state" "network" {
backend = "local" # Or "s3", "azurerm", etc., depending on your backend
config = {
path = "../network/terraform.tfstate" # Path to the network state file
}
}
resource "aws_instance" "app" {
ami = "ami-0abcdef1234567890" # Example AMI
instance_type = "t2.micro"
vpc_security_group_ids = [aws_security_group.app.id]
subnet_id = data.terraform_remote_state.network.outputs.public_subnet_id
}
resource "aws_security_group" "app" {
vpc_id = data.terraform_remote_state.network.outputs.vpc_id
# ... other security group rules
}
main.tf
By using this data source to pull the outputs, you know that you always have the latest outputs.
How to Use Outputs in Scalr and Terraform Cloud
Both Scalr and Terraform Cloud offer native ways to share outputs between workspaces/workspaces without manual terraform_remote_state configuration, simplifying dependency management.
Scalr & Terraform Cloud Shared Output Example:
In both Scalr and Terraform Cloud, the same terraform_remote_state code snippet can be used, but it is done with a slight difference. In Scalr, the hostname, environment, and workspace must be supplied so that the workspace pulling the outputs knows where the source is:
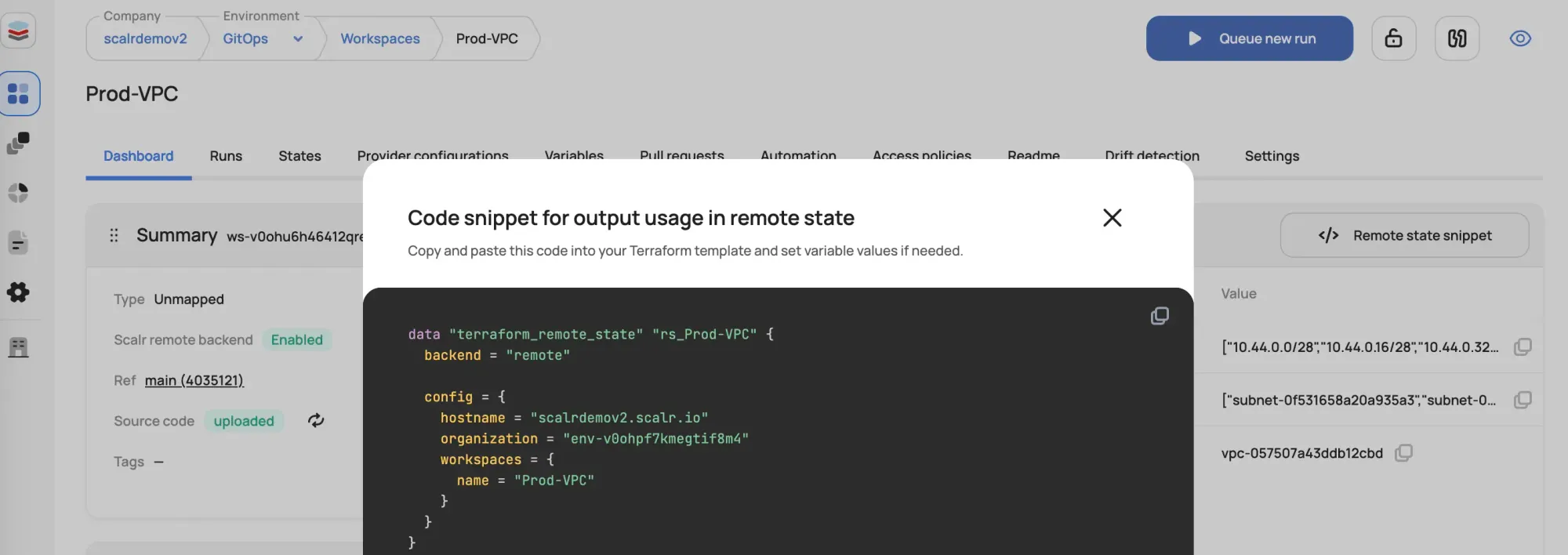
data "terraform_remote_state" "Prod-VPC" {
backend = "remote"
config = {
hostname = "your-account.scalr.io"
organization = "your-environment"
workspaces = {
name = "your-workspace"
}
}
}
#locals {
# subnet_cidrs = data.terraform_remote_state.rs_Prod-VPC.outputs.subnet_cidrs
# subnet_ids = data.terraform_remote_state.rs_Prod-VPC.outputs.subnet_ids
# vpc_id = data.terraform_remote_state.rs_Prod-VPC.outputs.vpc_id
#}In Terraform Cloud, it is very similar, but with some slight differences:
data "terraform_remote_state" "network" {
backend = "remote"
config = {
organization = "your-organization-name"
workspaces {
name = "workspace-name"
}
}
}This approach leverages the platform's ability to manage and expose outputs, making cross-workspace dependencies easier.